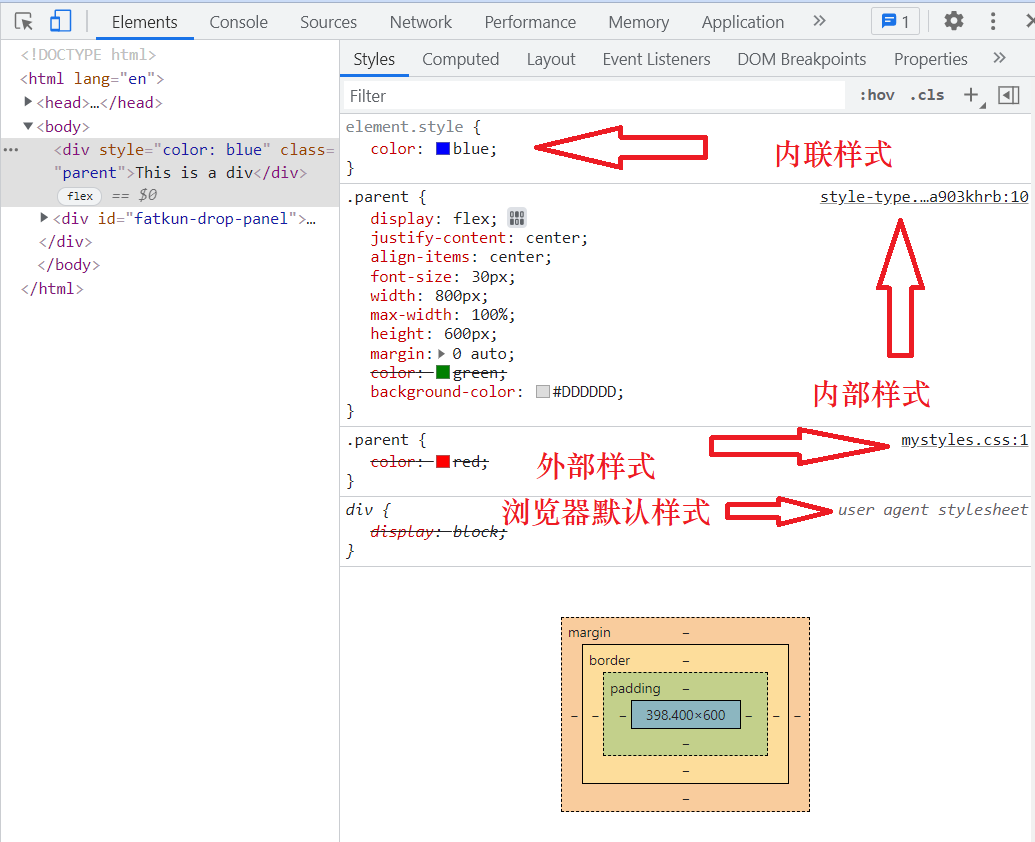
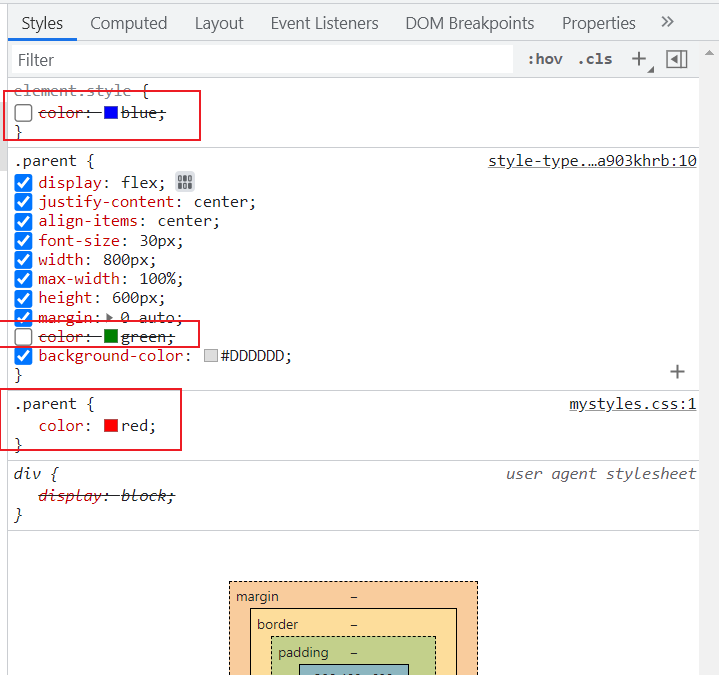
<!DOCTYPE html> <html> <head> <linkrel="stylesheet"type="text/css"href="mystyle.css"> </head> <body> <h1>This is a heading</h1> <p>This is a paragraph.</p> </body> </html>
Posted onEdited onInnx Symbols count in article: 125Reading time ≈1 mins.
Generate project with default styling file extension
Nx based monorepo can use file nx.json to config project generate options for specific frameworks. Take the following config as an example, when creating angular applications, nx will use scss as file extension for style files by default. If you want the terminal prompt you during the generation, remove the style option from the config.